
Nearly every company we work with has some amount of unstructured or text-based data that they collect from their customers and operations. Data from surveys, notes typed into CRM systems, emails, and more – all these unstructured text data sources can be a wealth of insight. And while everyone has this data, no one we’ve met is satisfied with the way they are leveraging text-based data.
IBM’s SPSS Modeler product includes a solution to this challenge – its Text Analytics workbench is designed to process, analyze, and understand written data. The TA component then gives you options for turning unstructured, free-form data into highly structured, usable insights.
Common uses for Text Analytics include:
- Examining data at the customer level to identify sentiment (positive, neutral, negative)
- Systematically identify keywords and topics that appear in the data
- Categorize or code transactions (or responses) into groups based on their content and/or sentiment
But let’s look closer at an example…
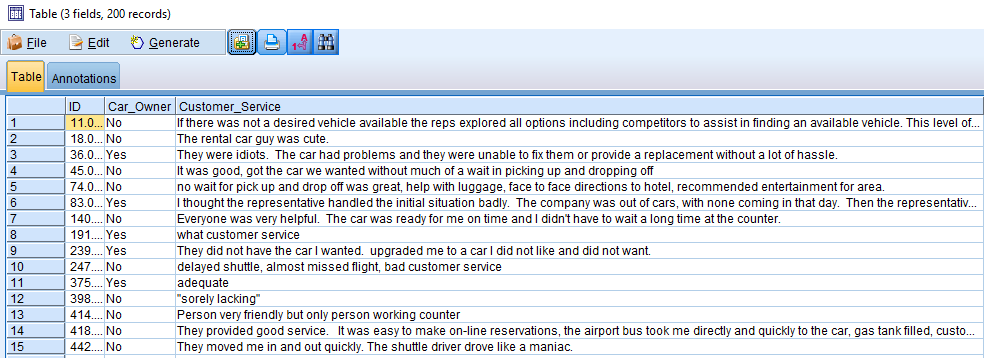
Revelwood Car Rental has just started sending its customers a satisfaction survey. The customer responses are below – insightful if you read each one, but how do you scale this up?
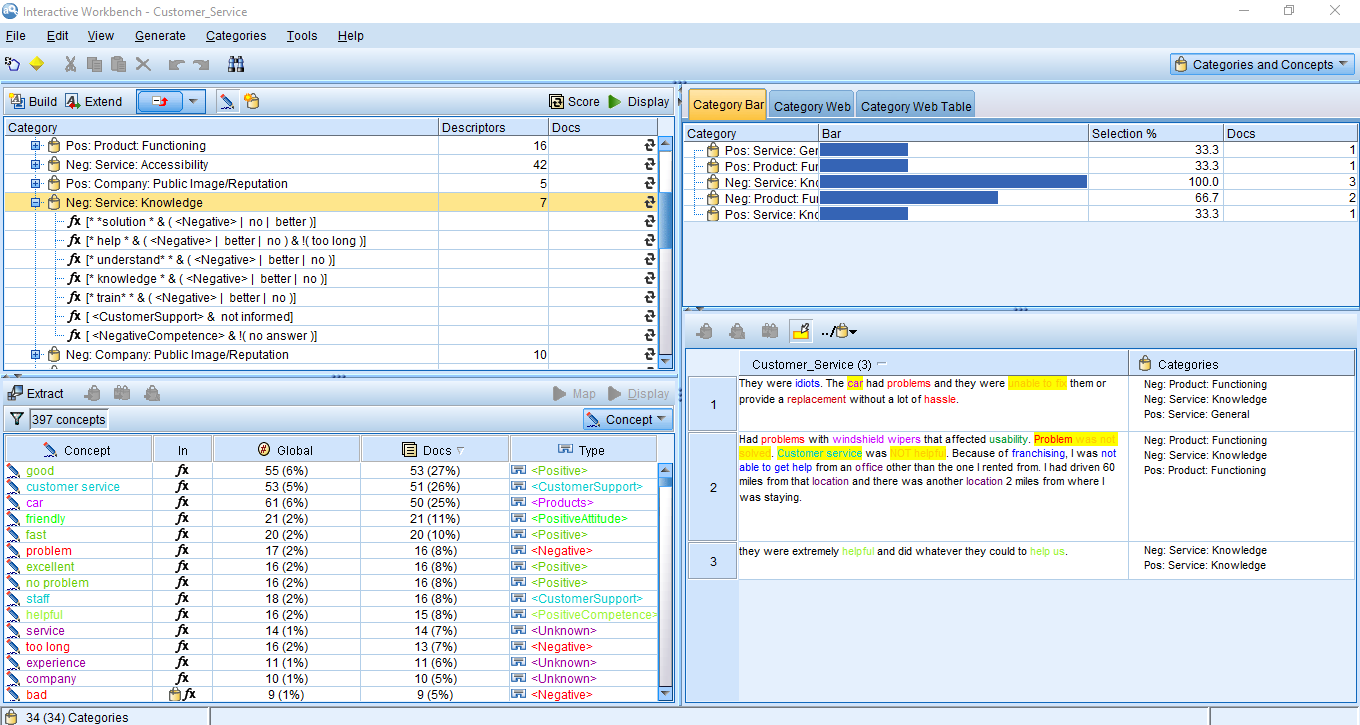
The Text Analytics workbench provides automatic concept extraction from the survey responses – that tells you what people are saying. You can then group topics into higher level categories to better manage and report on responses.
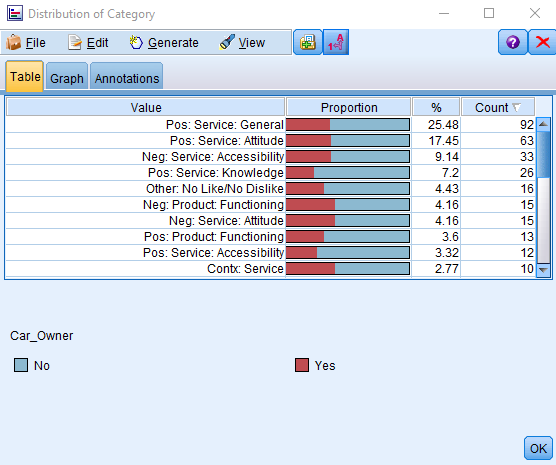
Finally, SPSS Modeler makes it easy to produce high-level stats on responses. Or better yet, you can feed this text insight into a customer retention or upsell model, where it will help directly drive incremental revenue.
Our clients who adopt this statistical approach to their data and business problems typically see dramatic returns on their effort. If you want to learn more about how get started with Text Analytics, or how to generate business results using text-based insights, contact us. We might just be able to help you pull a rabbit out of your hat – or at least out of your data.
